- NUMBERED ITEM 1
- NUMBERED ITEM 2
Contents
demo()
for i = 1:10 disp x end
- Comparing convergence traces produced by SFO and lbfgs, we can see that both optimizer converge to a similar optimal function value i.e. around 15. This can also be see from the reconstruction results that the reconstructed figures of Autoendoers trained by SFO and lbfgs respecitvely look very similar.
- Another obvious charater is the convergence trace produced by SFO is less smooth than the trace produced by lbfgs. This is bacause SFO train objective function on subfunction i.e. minibatches rather than on whole dataset that lbfgs does. Although the convergence trance is lesss smooth, SFO needs much less running time memory than lbfgs. And this feature will be more important in task with very large training dataset.
Numbered List
- NUMBERED ITEM 1
- NUMBERED ITEM 2
Case 1: successful update 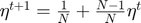
Case 2: failed update 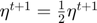
cartoon_pane_A = imread('figure_cartoon_pane_A.jpg'); cartoon_pane_B = imread('figure_cartoon_pane_B.jpg'); cartoon_pane_C = imread('figure_cartoon_pane_C.jpg'); figure,imagesc(cartoon_pane_A) figure,imagesc(cartoon_pane_B) figure,imagesc(cartoon_pane_C)
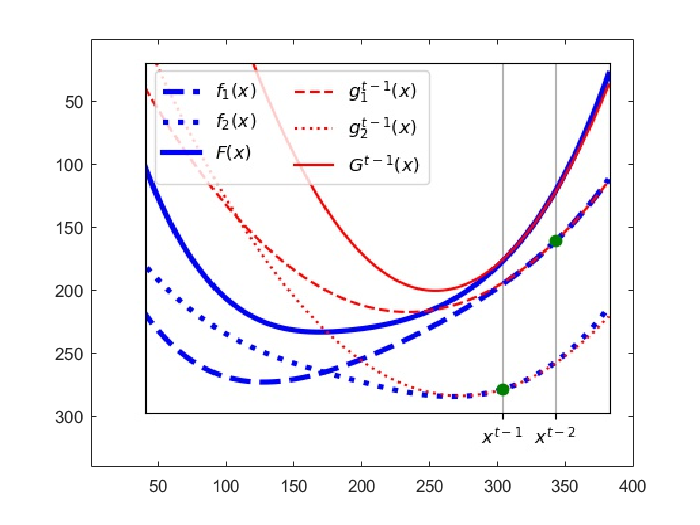
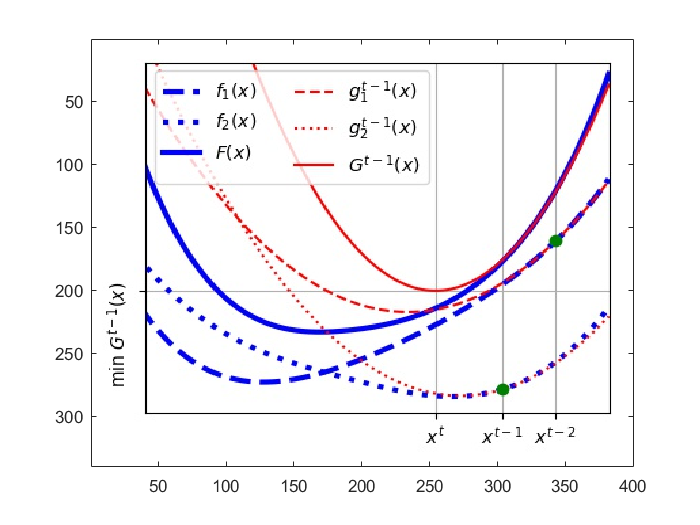
- Performe finally the Newton step according to Equation (5). (The Newton step length is adjusted in order to avoid numerical errors caused by small numbers or bouncing around opitimized values caused by large step size.)
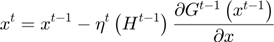 Equation(5) # Active subfunction set is expended in the end.
Equation(5) # Active subfunction set is expended in the end.
8. Analysis and conclusions
Experiment results analysis:
- Comparing convergence traces produced by SFO and lbfgs, we can see that both optimizer converge to a similar optimal function value i.e. around 15. This can also be see from the reconstruction results that the reconstructed figures of Autoendoers trained by SFO and lbfgs respecitvely look very similar.
- Another obvious charater is the convergence trace produced by SFO is less smooth than the trace produced by lbfgs. This is bacause SFO train objective function on subfunction i.e. minibatches rather than on whole dataset that lbfgs does. Although the convergence trance is lesss smooth, SFO needs much less running time memory than lbfgs. And this feature will be more important in task with very large training dataset.
- The way that SFO works on subfunctions of objective function also brings it a disadvantage in task with small dataset.
Overall conclusion:
# # #
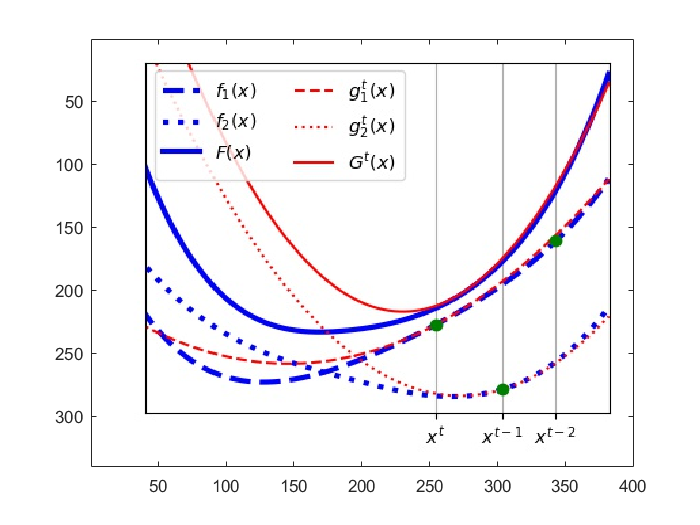
A vector 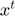 is chosen by minimizing the approximated objective function
is chosen by minimizing the approximated objective function 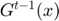 at the previous iteration by a Newton step.
at the previous iteration by a Newton step.