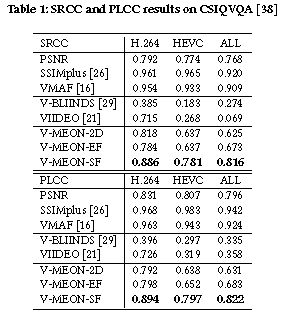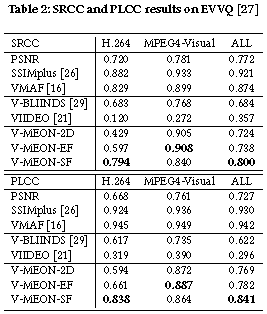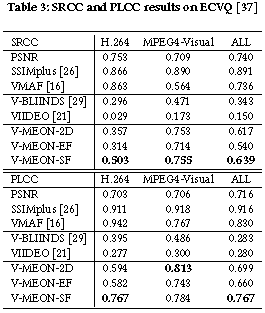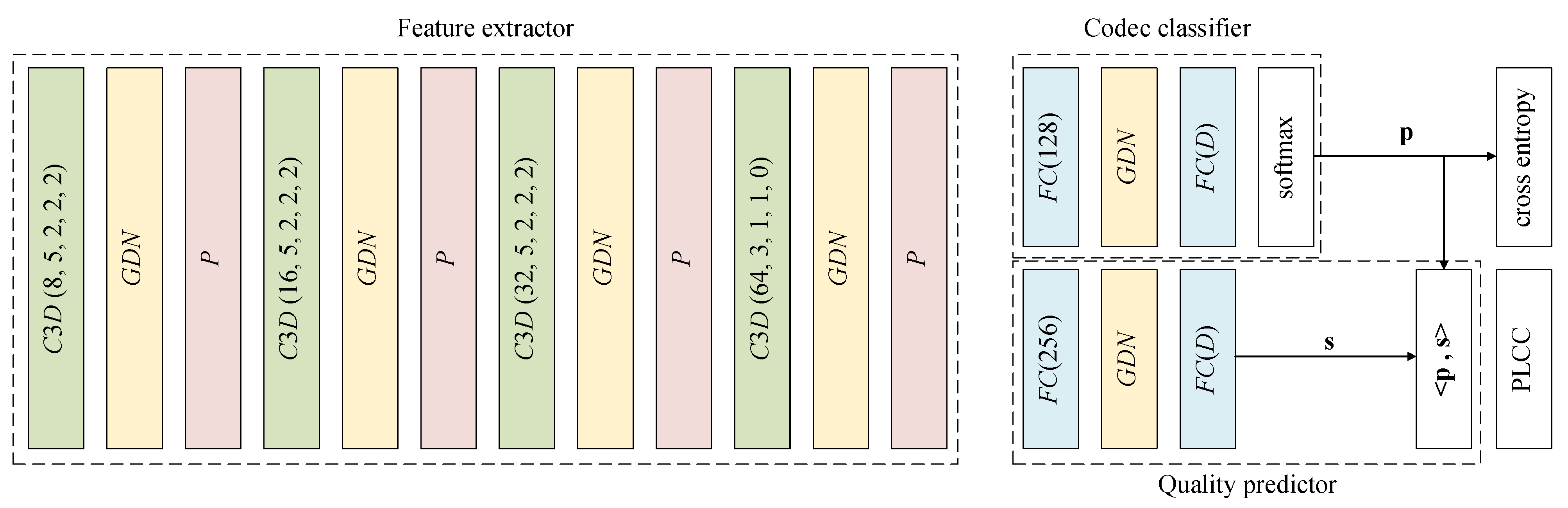
Blind video quality assessment (BVQA) algorithms are traditionally designed with a two-stage approach - a feature extraction stage that computes typically hand-crafted spatial and/or temporal features, and a regression stage working in the feature space that predicts the perceptual quality of the video. Unlike traditional methods, here we propose an end-to-end optimized BVQA model for compressed videos based on deep neural networks (DNNs) that merge the two stages into one, where the feature extractor and the regressor are jointly optimized. Our model uses a multi-task DNN framework that not only estimates the perceptual quality of the test video but also provides a probabilistic prediction of its codec type. This framework allows us to train the network with two complementary sets of labels, both of which can be obtained at low cost. The training process is composed of two steps. In the first step, early convolutional layers are pre-trained to extract spatiotemporal quality-related features with the codec classification subtask. In the second step, initialized with the pre-trained feature extractor, the whole network is jointly optimized with the two subtasks together. An additional critical step is the adoption of 3D convolutional layers, which creates novel spatiotemporal features that lead to a significant performance boost. Experimental results show that the proposed model clearly outperforms state-of-the-art BVQA methods.
@inproceedings{liu2018end,
title={End-to-End Blind Quality Assessment of Compressed Videos Using Deep Neural Networks},
author={Liu, Wentao and Duanmu, Zhengfang and Wang, Zhou},
booktitle={ACM Multimedia},
year={To appear}
}