Traveling salesman problem
Three implementations of the traveling salesman problem are provided:
- Top-down with a run time of
- Top-down using memoization with a run time of
- Bottom up with a run time of
We will solve the problem as follows: define tsp( S, k ) to be the minimum path from vertex v0 to vertex vk passing through the intermediate vertices in the set S. For example, as shown in Figure 1, the set S contains six elements, so this solution would be finding the optimal path of all 6! = 720 possible paths going between the two vertices v0 and vk.
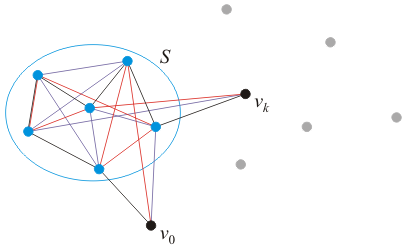
Figure 1. Finding the shortest path from v0 to vk through
all the vertices in the set S.
Thus, we would start with calling tsp( S \ {v0}, 0 ). Our implementations will pass the number of vertices n and an adjacency matrix as additional arguments. Then, in general,
where is the set S with everything in the set T removed and
is the weight of the edge between vertices
and
.
If the set S is empty, dst( {}, k ) is just the weight of the edge between vertices
v0 and vk.
Aside: if you look at other definitions of this algorithm, the definitions may be slightly different. This one was chosen specifically to simplify all the recursive definitions without additional cases being identified.
In each implementation, we will need to record a subset of a set of size n. We can use an integer between 0 to 2n − 1 where the kth bit represents the presence of the kth element. For example, given a set of size n = 5, 11111 represents the entire set, 00000 represents the empty set, and 00101 represents the set with the zeroth and second elements.
It is quite simple to iterate through the set using a mask:
int S = 53; // The set ...000110101
for ( int i = 0, mask = 1; i < n; ++i, mask <<= 1 ) {
if ( S & mask ) {
std::cout << "Element " << i << " is in the set" << std::endl;
}
}
In our case, the set S \ {v0} can be calculated as (1 << n) - 2, which would give us 11···110. If you want to calculate S \ {vk} where mask = 1 << k, we need only calculate S & ~mask, where ~mask is the bit-wise complement of mask, so if mask == 00000000000000000000000000010000, it follows that ~mask == 11111111111111111111111111101111, so S & ~mask keeps all 1s of S except for the fifth from the right.
When we run the test cases, the top-down implementation quickly shows factorial growth, with an estimate for solving a problem of size n = 15 at around forty-seven minutes. On the other hand, in the bottom-up implementation, to solve a problem of size n = 24, it is necessary to create a two-dimensional array of size 1.5 GiB. Note that floating-point numbers are used due to the size of the matrices and containers involved.
The run time of the implementations are shown in the table below.
| Size | Top-down | Top-down with memoization | Bottom-up |
|---|---|---|---|
| 3 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 |
| 5 | 0 | 0 | 0 |
| 6 | 0 | 0 | 0 |
| 7 | 0 | 0 | 0 |
| 8 | 0.0001 | 0 | 0 |
| 9 | 0.0021 | 0.0001 | 0.0001 |
| 10 | 0.0082 | 0.0011 | 0.0002 |
| 11 | 0.0942 | 0.0083 | 0.0005 |
| 12 | 1.0903 | 0.0134 | 0.0008 |
| 13 | 13.6917 | 0.0251 | 0.0025 |
| 14 | 186.9610 | 0.0586 | 0.0076 |
| 15 | - | 0.1472 | 0.0133 |
| 16 | - | 0.3751 | 0.0169 |
| 17 | - | 0.9546 | 0.0368 |
| 18 | - | 0.2507 | 0.0847 |
| 19 | - | 6.0352 | 0.1910 |
| 20 | - | 14.9473 | 0.4313 |
| 21 | - | 36.6500 | 0.9449 |
| 22 | - | 88.5540 | 2.1143 |
| 23 | - | 208.3919 | 4.3118 |
| 24 | - | 496.8036 | - |
These times are plotted in Figure 2. You will note the factorial growth of the default top-down implementation and the significant improvement that memoization makes; however, the bottom-up implementation requires just as much memory but fills it up methodically, and therefore the run-time is reduced by a factor of approximately 40.
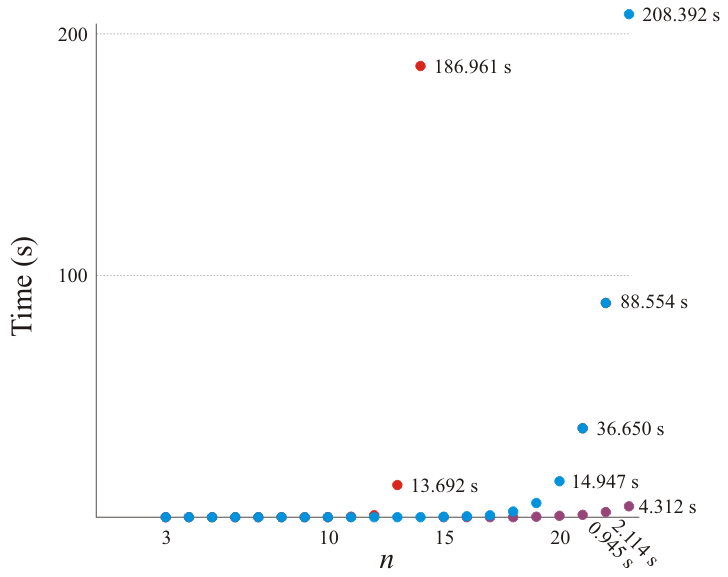
Figure 2. The run times of the various implementations of solutions to the traveling salesman problem.
Note that even if enough memory could be allocated, the bottom-up implementation would still require over an hour to solve a problem of size n = 33, a day to solve a problem of size n = 37, a year to solve a problem of size n = 45, and ecelinux would have to be solving the problem since the death of Pharaoh Ramesses II to solve a problem of size n = 55; such are the difficulties of exponential growth. The memory requirements are not so strenuous: for a problem of size n = 55, we would require 7 EiB, or 7,200,000 TiB, which could still easily fit within 64-bit memory.
To solve a problem of size n = 25 with the default top-down algorithm would require slightly more than one billion years; approximately as long as there has been multi-cellular life on this planet. Compare that to the approximate 20 seconds it would take to solve the same problem using the bottom-up algorithm; a difference of fifteen-and-a-quarter orders of magnitude. That is like comparing the distance to the Sun to the diameter of a human hair.
In either case, the moral of the story is: if you have to solve an NP Hard problem exactly, you will not be solving a very large problem. You will only be able to find an approximate optimal solution if you want to find solutions to very large problems. If, in addition, you do not use dynamic programming, you are going to be waiting a long, long time to get a solution, either that or you will simply not be able to solve very large problems.

Department of Electrical and Computer Engineering
University of Waterloo
200 University Avenue West
Waterloo, Ontario, Canada N2L 3G1
Website maintained by Douglas Wilhelm Harder